AI algorithm learns how to beat expert players at complex board game Stratego
DeepMind, a Google research company, has developed a system able to strategize against humans in a game infinitely more complex than chess or poker, opening new paths for science


The UK-based company DeepMind, which has been owned by Google since 2014, has developed an algorithm capable of playing the popular board game Stratego like an expert human player. As detailed by a team of DeepMind researchers in an article published on December 1 in the journal Science, DeepNash (as the tool has been christened) is already ranked within the top three players on the specialist Gravon games platform, where it has been competing against human opponents. This represents a milestone due to the high complexity of the game, which combines elements of strategy, intuition (players do not have all the necessary information available to draw up perfect plans) and even bluffing. The authors of the study believe that the algorithm could be applied in areas such as automatic traffic optimization.
Marketed by Jumbo Games since the 1960s, though invented before World War I in a very similiar format under the French name L’Attaque, Stratego was one of the few board games not yet mastered by artificial intelligence. Stratego is characterized by a double challenge: it requires long-term strategic thinking, like chess, but you also need to manage imperfect information, as in poker, because the opponent’s chips are covered at the start of the game and only revealed as it progresses. This uniqueness makes it a more complex game than Go, the 1,000-year-old Asian game whose board allows the tiles to be arranged in more different combinations than there are atoms in the universe. It also means that winning requires more cunning than in poker – where you don’t know your opponent’s cards either – and players require both intuition and mathematical knowledge.
Game simulators have historically served as a good barometer to measure the effectiveness of computer programs. They offer a controlled environment with precise rules in which the tools can develop their abilities and where it is easy to measure their success: researchers simply have to see if they win the game or not. It is a perfect litmus test to study how humans and machines develop and execute game-winning strategies. As such, DeepMind decided to set its sights on Stratego, a major challenge for the machine given the lack of information that it must manage during the game.
DeepMind has a long history in the field, having developed cutting-edge tools to outperform humans in complex, long-term strategy games with perfect information, such as Go (using AphaGo), but also in imperfect information video games, such as StarCraft (using AlphaStar). Until now, no-one had managed to develop a tool capable of playing Stratego at the same level as an expert human. This is no coincidence: the game has 10⁵³⁵ possible dispositions, considerably more than Texas Hold’em poker, a game of imperfect information with 10¹⁶⁴ possibilities in which players know only what cards they have in their hand and those that are in play, or Go, which has 10³⁶⁰ options.
On the other hand, any move made on the first turn involves thinking of 10⁶⁶ possible pairs of chip configurations. In poker, that figure is 10⁶. Perfect information games do not present the same problem, as the chips are in plain sight.
These two particular complexities make it impossible to take advantage of previous research to approach a game simulator for Stratego. For this reason, the DeepMind team has developed a reinforcement learning algorithm that applies theoretical models based on Nash equilibrium, a theorem developed by American mathematician John Nash, a specialist in game theory. The tool does not try to predict the possible moves an opponent may make, which is the standard approximation in game simulators – because the number of possibilities in the game tree is practically infinite – but instead establishes its own strategy and then adapts it based on how the game pans out.
“Our paper shows how DeepNash can be applied in situations of uncertainty and successfully balance its actions to help solve complex problems,” explains Julien Perolat, lead author of the study. Perolat and his colleagues believe that R-NaD, the algorithm behind DeepNash, can be useful for developing new artificial intelligence applications that involve interaction with many humans with differing objectives, which implies that the system has a lack of information about what is going to happen.

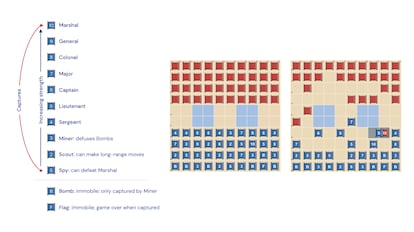
How to play Stratego
Stratego is enjoying a renaissance thanks to the internet. The popular board game has now made its way onto forums such as Gravon, where players from around the world square off against each other in tense online matches.
In Stratego, two players take turns playing against each other using 40 pieces with different attributes on each side of the board. The objective of the game is to capture the opponent’s flag, or to leave them without any remaining movable pieces. To do this, the players take turns moving their movable pieces one step horizontally or vertically – the bomb and the flag are not movable – and these correspond to military ranks ranging from sergeant to marshal and specialists such as miners, scouts or spies. Each time a piece comes into contact with an opponent’s piece, both are revealed. The one that has a higher rank or special ability wins and remains on the board. The losing piece is removed from the game.
The DeepNash algorithm is capable of developing unpredictable strategies and executing equivalent moves in a seemingly random manner. This is designed to confuse an opponent so that they cannot draw conclusions about the machine’s playing style. In one of the games reviewed in the article, for example, DeepNash sacrificed two valuable pieces to locate the opponent’s higher-ranked pieces. That left it at a material disadvantage, but the algorithm understood that possessing information about the location of the opponent’s most valuable pieces gave it a 70% chance of success. DeepNash won that game. In another game it played a bluff, chasing a high-ranking piece with a very low-ranking piece, which led to the opponent being convinced that the algorithm was playing a marshal (10) and bringing out a spy (S) in response, a strategic piece that he lost to a scout (2).
“DeepNash’s level of play surprised me. I had never seen a machine capable of playing Stratego like an experienced human player. After playing against DeepNash myself, I was not surprised that it made it into the top-three of the Gravon ranking. I think it would do very well if they let it participate in the World Championship,” says Vincent de Boer, co-author of the Science paper and a former Stratego world champion.
Sign up for our weekly newsletter to get more English-language news coverage from EL PAÍS USA Edition









































